A Citizen-Led Crowdsourcing Roadmap for the CI-BER Big Data Project
March 2013
Priscilla Ndiaye (Asheville Southside Community Advisory Board)
Dwight Mullen (UNC Asheville - Political Science)
Richard Marciano (UNC Chapel Hill / SALT Lab)
Cathy Davidson (Duke / HASTAC)
Robert Calderbank (Duke / iiD)
Sheryl Grant (Duke / HASTAC)
Mandy Dailey (Duke / HASTAC)
Kristan Shawgo (Duke / HASTAC)
Jeff Heard (UNC Chapel Hill / RENCI)
Introduction
“[A]t a time when the web is simultaneously transforming the way in which people collaborate and communicate, and merging the spaces which the academic and non-academic communities inhabit, it has never been more important to consider the role which public communities - connected or otherwise - have come to play.” (Dunn & Hedges, 2012.)
This statement is especially true for the CI-BER project, a collaborative “big data” project based on the integration of heterogeneous datasets and multi-source historical and digital collections, including a place-based case study of the Southside neighborhood in Asheville, North Carolina. The CI-BER team is in the process of assembling historical and born-digital collections that span decades of urban development and demographic data and include heterogeneous records of 1930s New Deal policies, 1940 Census data, 1960/70s Urban Renewal policies, and contemporary planning data. Members of the CI-BER project are automating and integrating temporal and spatial datasets such as census, economic, historic, planning, insurance, scientific, and financial content. The next task is to co-create a crowdsourcing process to solicit feedback from community members that will accelerate the data identification process. Crowdsourcing is becoming an increasingly popular technique in dealing with “big data” processing and management.
What sets CI-BER apart from a straightforward digitization or visualization project is its deployment of crowdsourcing, in which the community is an essential part of the design and implementation process. Crowdsourcing is “the process of leveraging public participation in or contributions to projects and activities,” and can be carried out in different ways depending on the community involved, the content to be crowdsourced, and the technology available. This document outlines a four-phase crowdsourcing process designed with and for the Southside Asheville community.
In the sections below, we outline the 1) crowdsourcing framework, 2) community history, 3) remapping process, and propose a 4) citizen-led crowdsourcing process in four proposed phases that describe possible relationships and workflow. The CI-BER project is a highly iterative and collaborative project, and feedback is both welcome and necessary.
I. Crowdsourcing Framework
Our overall frame for how we approach crowdsourcing takes as inspiration the policies of the Obama administration and the nation’s recordkeeper, the National Archives and Records Administration (NARA):
“...Our commitment to openness means more than simply informing the American people about how decisions are made. It means recognizing that the Government does not have all the answers, and that public officials need to draw on what citizens know. And that’s why, as of today, I’m directing members of my administration to find new ways of tapping the knowledge and experience of ordinary Americans. . . .’” (David Ferriero, quoting President Obama, 2009).
Drawing on what citizens know and want to know is at the heart of how CI-BER approaches crowdsourcing. The involvement of Asheville’s Southside community in co-creating and designing the process is of paramount importance to its success. In their Crowdsourcing Scoping Study, Dunn and Hedges (2012) refer to three types of crowdsourcing approaches: contributory, collaborative, and co-created. CI-BER proposes a process of co-creation, in which the community is actively involved in most or all steps of crowdsourcing. We refer to this as citizen-led crowdsourcing, and take initiative from the community based on their energetic and vital participation in an earlier North Carolina Humanities Council (NCHC) project called Twilight of a Neighborhood: Asheville’s East End, 1970.
CI-BER’s use of the term “citizen-led sourcing” is inspired by the Obama administration’s Open Government Initiative, which encourages public participation and collaboration. It is a derivative of the term citizen sourcing which has been defined as the “government adoption of crowdsourcing techniques for the purposes of (1) enlisting citizens in the design and execution of government services and to (2) tapping into the citizenry’s collective intelligence.” Vivek Kundra, Chief Information Officer of the United States from March 2009 to August 2011 under President Obama, described citizen sourcing as a way of driving “innovation by tapping into the ingenuity of the American people to solve those problems that are too big for government to solve on its own.” Citizen sourcing is derived from the term crowdsourcing and emphasizes the type of civic engagement typically enabled through Web 2.0 participatory technologies, over a more impersonal crowd-based distributed problem-solving and production model.
In the International Journal of Public Participation article, Citizensourcing: Applying the Concept of Open Innovation to the Public Sector, the authors present “a structural overview of how external collaboration and innovation between citizens and public administrations can offer new ways of citizen integration and participation, enhancing public value creation and even the political decision-making process.”
The Archivist of the United States, David Ferriero, has also introduced the concept of “citizen archivists” in 2010. He made a parallel with citizen scientists and spoke of increasing public engagement in the archives given the National Archives and Records Administration’s over-abundance of paper records and need to digitize and transcribe them. Finally, more recently, at the August 2011 Society of American Archivists (SAA) annual meeting in Chicago, Robert Townsend, Deputy Director of the American Historical Association, chaired a session examining the notion of “participatory archives.” The panelists Kate Theimer, Elizabeth Yakel, and Alexandra Eveleigh provided a definition and examples of participatory archives, discussing the latest research on the impact of user participation. Kate Theimer offered the following definition:
Participatory Archive: An organization, site or collection in which people other than archives professionals contribute “knowledge or resources, resulting in increased understanding about archival materials, usually in an online environment.”
This definition is very useful as it relates to the notion of “citizen-led sourcing” we propose. Our citizen-led focus puts civically engaged community members at the forefront and indicates that the focus is on the community engaging the archive with control resting on their shoulders.

Fig. 1: From crowdsourcing to citizen-led sourcing (dates indicate when concepts were first introduced)
II. The Community
In 2008, the North Carolina Humanities Council sponsored Twilight of a Neighborhood, which was organized around the photographs of Andrea Clark who had documented the community’s life at the eve of urban renewal. This project, and the earlier October 2007 transfer of a nearly intact and complete collection of urban renewal documents from the City to the University of North Carolina Asheville Library, helped energize “an emerging movement of concerned Asheville citizens who believe that their culture and history will shape how they live in the present and define the future.”
The CI-BER crowdsourcing project builds on this vital community interest and energy, and works with displaced citizens and African American community leaders who participated in the North Carolina Humanities Council project. The purpose is to put technology at the service of the community to document, analyze, and represent its lost history, and help reclaim it for education benefits, awareness, civic action, and potentially economic development purposes.
In October 2007, the Asheville City Council approved the transfer of the records of the Housing Authority of the City of Asheville (HACA) to the D.H. Ramsey Library Special Collections & University Archives at the University of North Carolina Asheville (UNCA). This collection of nearly 130 linear feet and some 129 cartons, documents a number of “significant redevelopment projects undertaken from the early 1960s to the mid-1980s.”
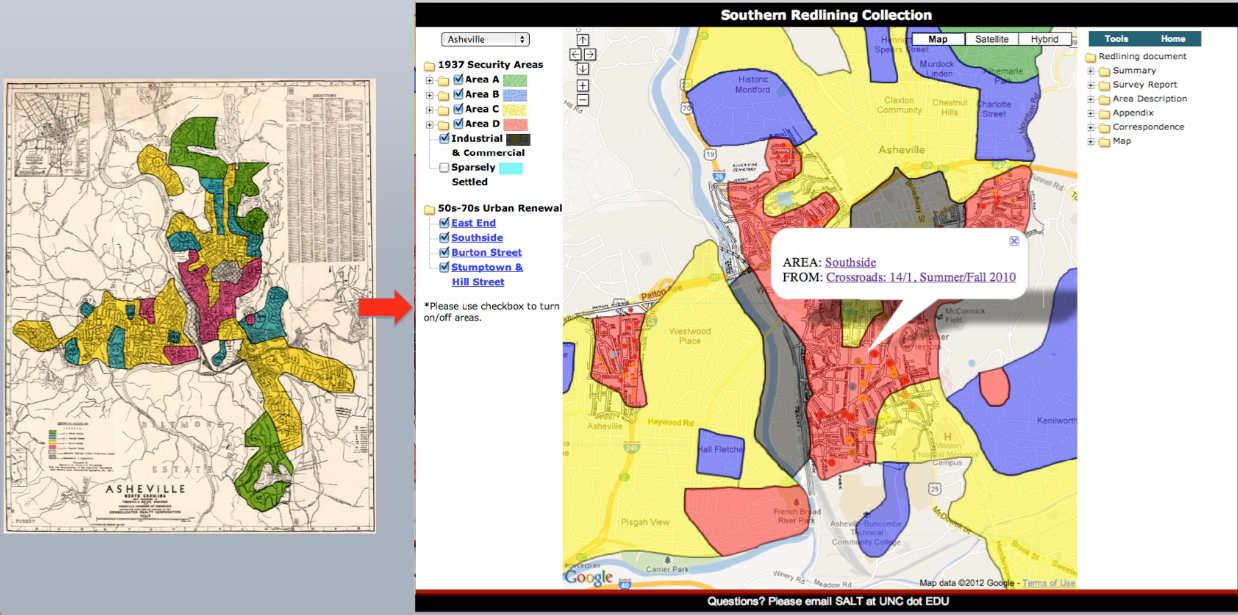
CI-BER focuses on the Southside project (formerly known as East Riverside), which at over 400 acres was the largest urban renewal area in the southeastern United States. In 1966, the Southside community represented about 4,000 people, some 7% of the population, living in nearly 1,300 households, and 98% African American, housing “more than half of the Negro families in the City of Asheville.” “The scale of devastation here was unmatched with more than 1,100 homes lost.” The urban renewal African American experience in Asheville is one of painful displacement and fragmentation.
Urban renewal as a federal government program was a 24-year (1949-1973) initiative started under the Housing Act of 1949, and modified under the Housing Act of 1954. It used the 1930’s Home Owners’ Loan Corporation (HOLC) redlining terminology of “blight” and “slums” to launch an ambitious redevelopment and eminent domain process that led to the bulldozing of some 2,500 neighborhoods in 993 American cities. It is estimated that one million people were dispossessed in the process. “Black America cannot be understood without a full and complete accounting of the social, economic, cultural, political, and emotional losses that followed the bulldozing of 1,600 neighborhoods,” wrote Mindi Fullilove, who added that “the obliteration of a neighborhood destroys the matrix that holds people together on particular paths and in specific relationships.”
Community project consultant Priscilla Ndiaye is a Southside native, a community leader, and the Chair of the Southside Community Advisory Board, which was housed in the W.C. Center in the former Livingston Street School building, one of the very few original neighborhood buildings standing. She and community members, Nikoletta and Alonzo Robinson, led the collection indexing and mapping effort in March 2013. University of North Carolina-Asheville project director Dr. Dwight Mullen is a professor of Political Science, and as the lead partner at UNCA, directed four students in the digitization of initial portions of the collection from January to March 2013. The digitization team also included Donnell Sloan, Noor Al-Sibai, Anna McGuire, and Jesse Rice-Evans. This work was enabled through generous support of UNCA’s University Librarian, Leah Dunn, and Special Collections staff, Colin Reeve and Laura Gardner.
III. Remapping the Community
In essence, the CI-BER crowdsourcing approach harnesses the power of engaged citizens who can help capture key elements (owner, renter, parcel number, street address) per scanned documents (initial appraisal sheet, and house photo), and rapidly remap the entire Southside neighborhood. CI-BER’s technical team will use this information with fragments of maps found in the collection to create a digital spatial canvas of the entire neighborhood in 1965 on the eve of urban renewal, where each parcel is clickable and linked to its key elements.
The goal is to recreate community and bring to life the entire collection in the very first iteration. Priscilla Ndiaye demonstrated the vitality of this process when she pulled various property acquisition folders from Southside boxes, and came across the house she was born in, the house she grew up in, and houses of friends, neighbors, and community members. Being able to reproduce this process online and identify and tag collection items is one of the goals of our citizen-led sourcing of the archive. The community carries the living history of these records. Through iterative and incremental passes over the files, the CI-BER team will gradually make sense of the collection, digitize strategic content, transcribe it through citizen-led crowdsourcing, visualize and map the content, enhance the collection, develop a working content model, and add functionality to the software user interface being built.
IV. Citizen-led Crowdsourcing
The CI-BER project uses an incremental agile development-like approach. During our first pass, we are producing an initial neighborhood map that serves as a starting canvas in space and time. As new iteration loops take place throughout March and April of 2013, neighborhood residents will be able to follow the progress, provide feedback, and upload additional content to ensure transparency and openness: “ensuring the community is in the loop.” CI-BER’s citizen-led focus puts civically engaged community members at the forefront so that control rests on their shoulders.
We propose a workflow in four phases, based on best practices from theCommunity History Digitization: How-To Manual and Exercises.
Phase 1: Student- and citizen-led crowdsourced digitization, indexing, and mapping (completed)
January-March 2013
January-March 2013
- Community member and student-driven digitization of an initial subset of the collection.
- Community-led indexing and mapping of the collection.
Phase 2: Modeling and motivating community participation in the crowdsourcing design process
March-May 2013
March-May 2013
- Develop programming that can be used to build community buy-in around the project in its developmental stages.
- We are working with Jeff Heard from RENCI and modifying the “Big Board” emergency mapping software to accommodate crowdsourcing capabilities.
April-June 2013
- Develop a framework for the crowdsourcing logistics.
- Evaluate other community-based historical digitization projects
- Develop a wishlist of features to help guide the design of the crowdsourcing interface.
Summer 2013
- Rollout of project through a series of public events.
V. References
Dunn, S., & Hedges, M. (2012). Crowd-sourcing scoping study: Engaging the crowd with humanities research. Centre for e-Research, Department of Digital Humanities King’s College London. Arts & Humanities Research Council. A project of the AHRC Connected Communities Theme. Retrieved from http://humanitiescrowds.org/2012/12/21/final-report/Ferriero, D. (2013). Volunteers help NARA do its job, support professional archivists. Archival Outlook. January/February 2013, p. 16. Society of American Archivists.
Fullilove, M. (2004). Root Shock: How Tearing Up City Neighborhoods Hurts America, and What We Can Do About It. New York: One World/Ballantine Books.
Judson, S. (2010). Twilight of a neighborhood: Asheville’s East End, 1970. Crossroads: A Publication of the North Carolina Humanities Council. Summer/Fall 2010. Retrieved fromhttp://nchumanities.org/sites/default/files/documents/Crossroads%20Summer%202010%20for%20web.pdf
Hilgers, D., & Ihl, C. (2010). Citizensourcing: Applying the concept of open innovation to the public sector, The International Journal of Public Participation, 4:1. Retrieved fromhttp://www.iap2.org/associations/4748/files/Journal_10January_Vol4_No1_6...